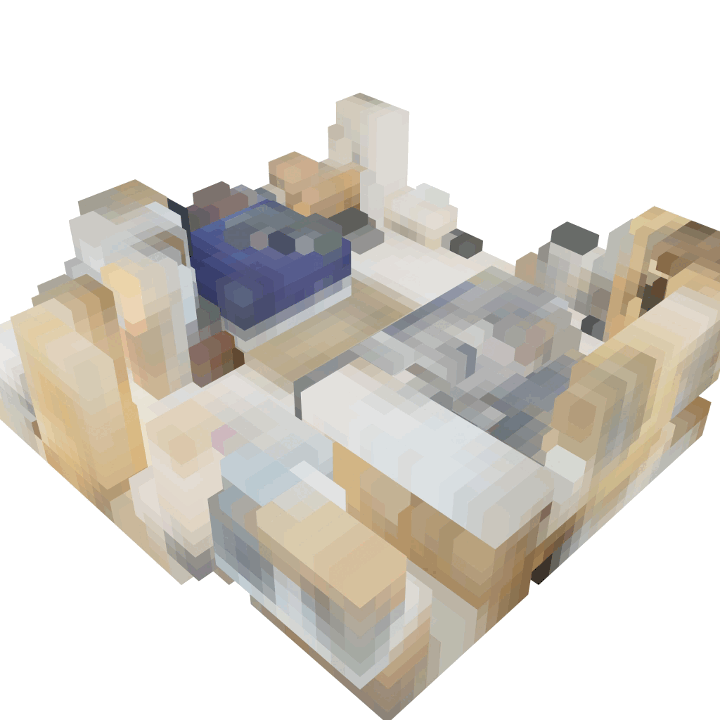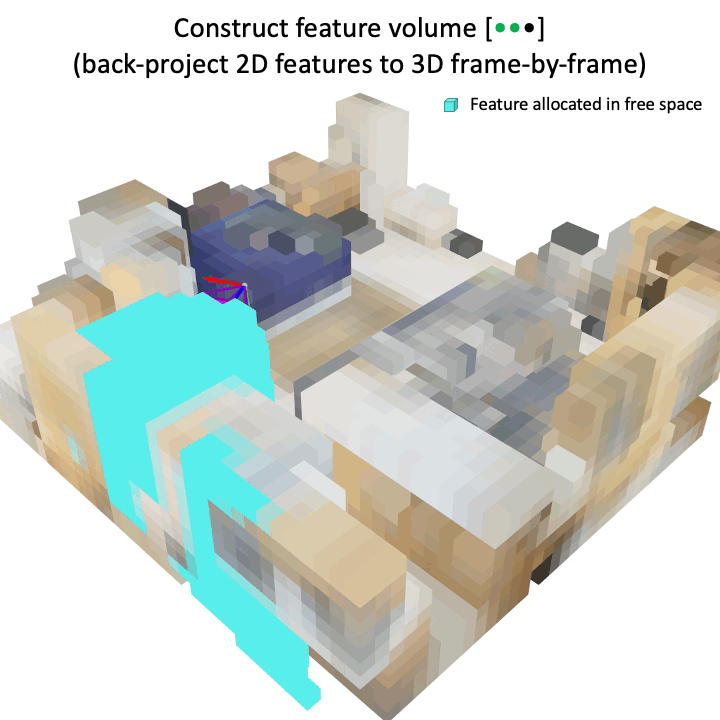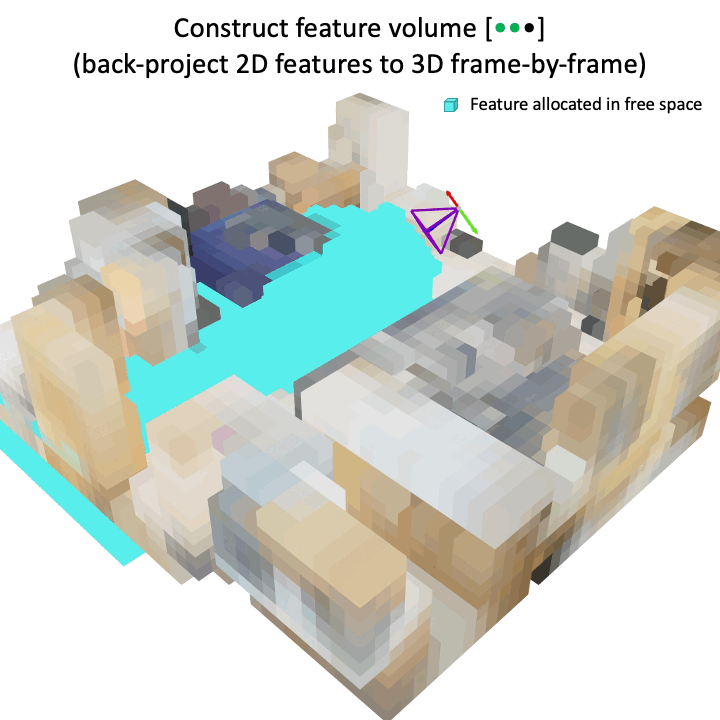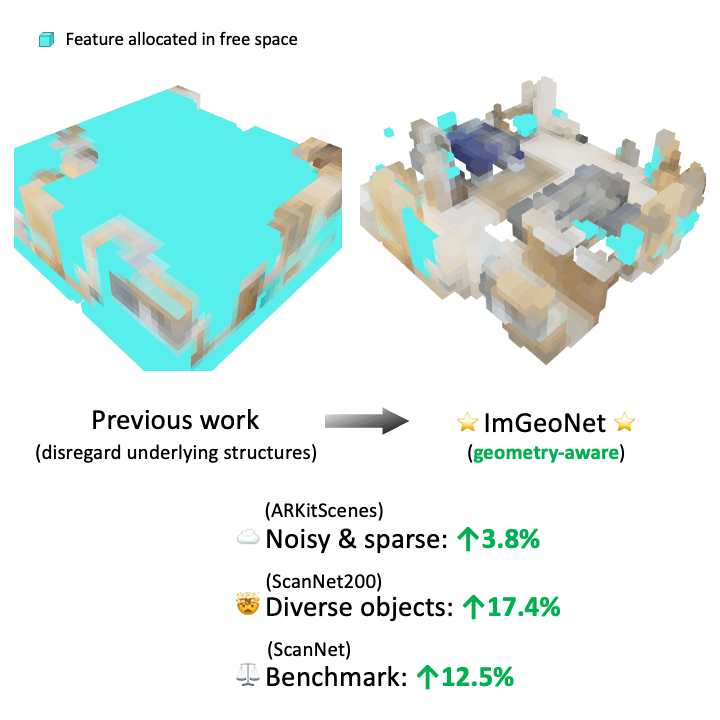
In contrast to prior works that disregard the underlying geometry by directly averaging feature volume across multiple views, our proposed successfully preserves the geometric structure with respect to the ground truth while effectively reducing the number of voxels in free space. This geometry-aware voxel representation significantly improves 3D object detection performance.
Abstract
We propose ImGeoNet, a multi-view image-based 3D object detection framework that models a 3D space by an image-induced geometry-aware voxel representation. Unlike previous methods which aggregate 2D features into 3D voxels without considering geometry, ImGeoNet learns to induce geometry from multi-view images to alleviate the confusion arising from voxels of free space, and during the inference phase, only images from multiple views are required. Besides, a powerful pre-trained 2D feature extractor can be leveraged by our representation, leading to a more robust performance.
To evaluate the effectiveness of ImGeoNet, we conduct quantitative and qualitative experiments on three indoor datasets, namely ARKitScenes, ScanNetV2, and ScanNet200. The results demonstrate that ImGeoNet outperforms the current state-of-the-art multi-view image-based method, ImVoxelNet, on all three datasets in terms of detection accuracy. In addition, ImGeoNet shows great data efficiency by achieving results comparable to ImVoxelNet with 100 views while utilizing only 40 views. Furthermore, our studies indicate that our proposed image-induced geometry-aware representation can enable image-based methods to attain superior detection accuracy than the seminal point cloud-based method, VoteNet, in two practical scenarios: (1) scenarios where point clouds are sparse and noisy, such as in ARKitScenes, and (2) scenarios involve diverse object classes, particularly classes of small objects, as in the case in ScanNet200.
ImGeoNet
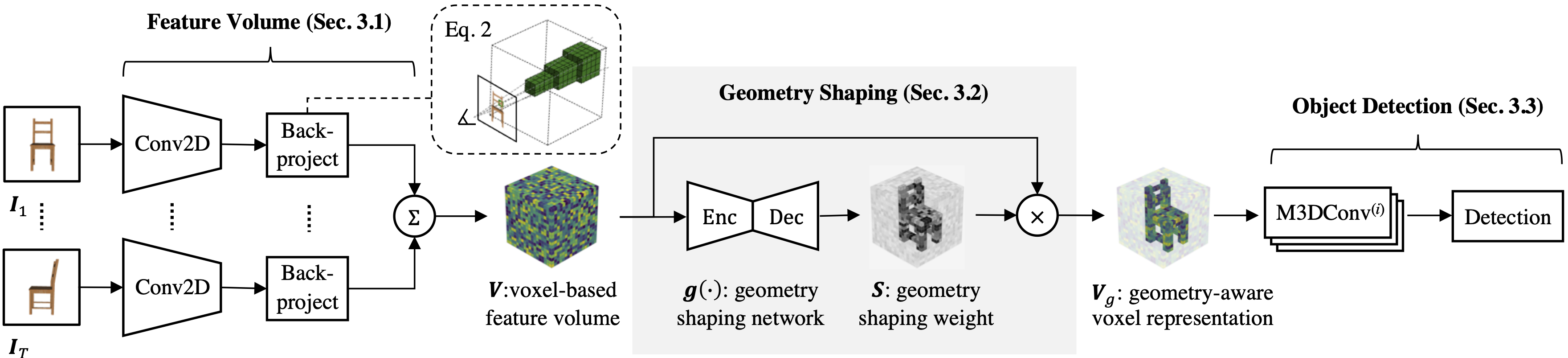
Given an arbitrary number of images, a 2D convolution backbone (Conv2D) is applied to extract visual features from each image, and then a 3D voxel feature volume is constructed by back-projecting and accumulating 2D features to the volume. This feature volume is not ideal since the underlying geometry of the scene is not considered. Hence, the proposed geometry shaping is applied to weight the original feature volume by the predicted surface probabilities, which preserves the geometric structure and removes voxels of free space. Finally, the geometry-aware volume is passed to the multiscale 3D convolutional layers (M3DConv) and the detection head.
Quantitative Results
| Method | Input | (1) Noisy & sparse ☁️ | (2) Diverse objects 🤯 | (3) Benchmark ⚖️ | ||
|---|---|---|---|---|---|---|
| mAP@0.25 | mAP@0.5 | mAP@0.25 | mAP@0.25 | mAP@0.5 | ||
| ImGeoNet | RGB | 60.2 | 43.4 | 22.3 | 54.8 | 28.4 |
| ImVoxelNet | RGB | 58.0 | 38.8 | 19.0 | 48.7 | 23.8 |
| VoteNet | Point cloud (costly!!) | 53.3 | 38.5 | 19.8 | 58.6 | 33.5 |
In practical situations, (1) depth images often exhibit noise and sparsity, as seen in ARKitScenes, and (2) objects can display considerable variation, as exemplified by ScanNet200. We demonstrate that ImGeoNet surpasses prior techniques in addressing these real-world conditions. (3) Lastly, we evaluate ImGeoNet against previous approaches using the standardized ScanNet benchmark, comprising superior depth images and point clouds. Although VoteNet exhibits superior accuracy in this case, it's worth noting that point cloud-based methods are constrained by reliance on expensive 3D sensor data.
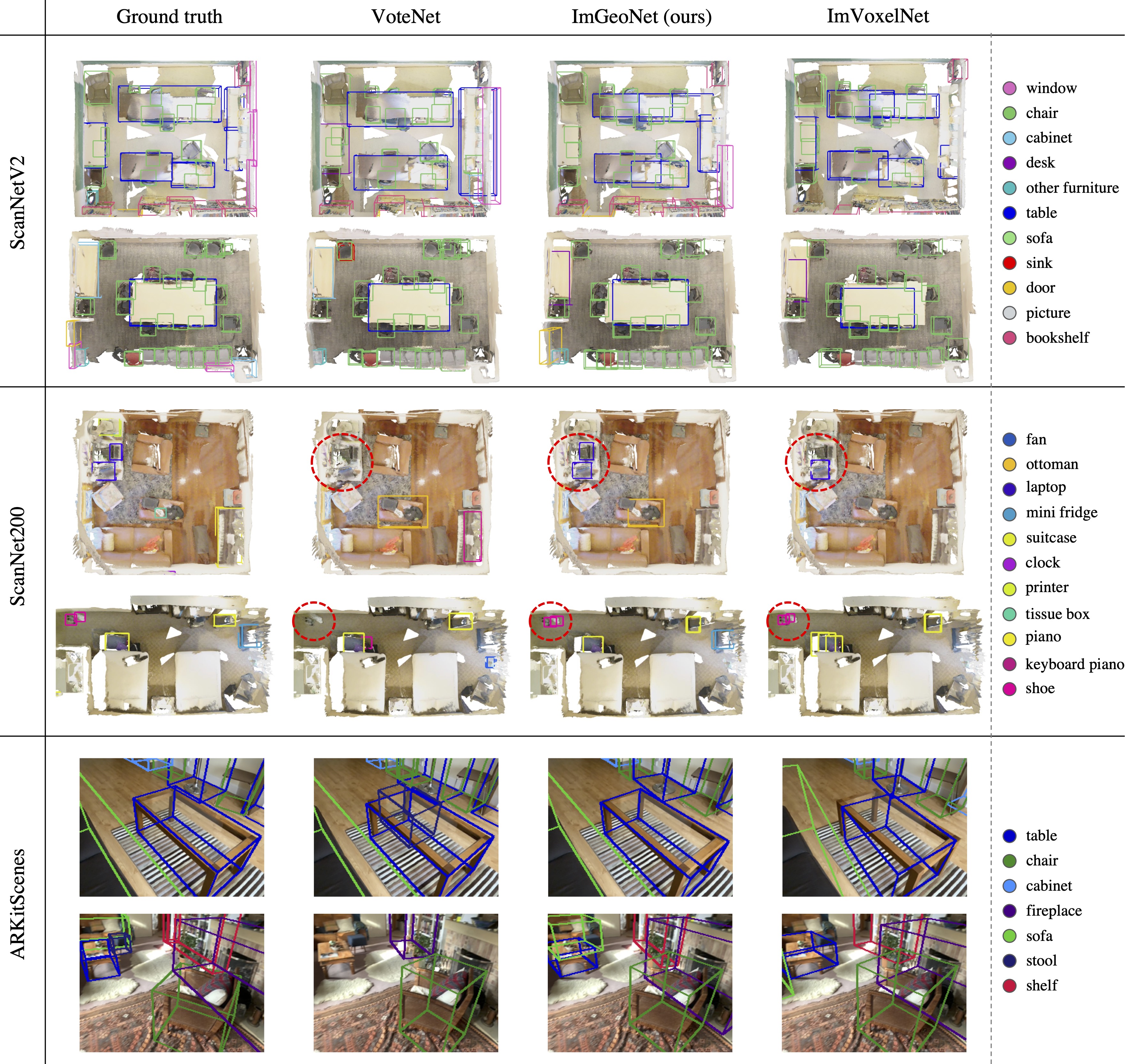
Qualitative Results